
We believe that cryptocurrency is the future. As our CEO Michael Gronager explained in a recent blog post, we expect that blockchains will soon be the world’s primary mechanism for the exchange of value, just as the internet has become the primary mechanism for the exchange of information. Our mission is deeply tied to that future — by building trust in blockchains, we’re working to set the stage for mass adoption of crypto in a way that gives participants safety and security. But how are we doing that on a practical level? By building the world’s most robust knowledge graph of blockchain activity, so that stakeholders across the public and private sectors can see the entities transacting on-chain, the activity those entities are involved in, and the connections between them.
At its core, that knowledge graph is made up of raw, public on-chain data augmented by Chainalysis attributions of cryptocurrency addresses to specific services or wallets, plus our ability to then group together more addresses belonging to each service or wallet in a process we call clustering. Given our long-term mission, as well as the more immediate fact that our solutions are used to detect and investigate criminal activity, it’s of the utmost importance that our attribution and clustering of blockchain entities be accurate and verifiable. For that reason, we take a conservative approach and only attribute addresses to a service or wallet when we have ground truth data — meaning directly observable, empirical evidence — demonstrating that the address belongs to that service or wallet. We only then cluster new addresses together with those ground truth addresses on a deterministic basis. Deterministic methods of data analysis will always yield the same outputs when given the same inputs because they operate based on a set of predefined rules — in the case of our clustering process, those rules are based on the empirically observed on-chain behavior of wallets and services.
In other words, the information users see in Chainalysis solutions is there because it’s accurate. Our approach to address attribution and clustering allows us to live up to three important principles:
-
- Consistency of results. Ground truth attributions and deterministic clustering mean that our solutions always produce the same measurements of any service or wallet’s on-chain activity given the same data inputs. [1]
- Auditability and transparency. Since our methods always produce the same results given the same data inputs, those results are fully auditable. Unlike probabilistic methods, the deterministic clustering process enables us to reconstruct a cluster representing a service from scratch step by step. This auditability also makes internal peer review possible and provides unparalleled transparency into how we arrived at our conclusions. As such, law enforcement agencies can conduct their own investigations to verify our conclusions for prosecutions.
- Always backed by human review. A ground truth standard for address attribution requires that humans start the process by personally verifying the ground truth data used to attribute an address to a given wallet or service. Other humans then double check that verification. Next, deterministic clustering identifies further addresses belonging to that wallet or service based on rules created, reviewed, and constantly improved by humans. Finally, automation and humans also watch for evidence that a service has changed its on-chain behavior or infrastructure in a way that limits our ability to continuously cluster more of its addresses — if it has, we need to come up with new clustering methods. This is a major differentiator from blockchain analysis tools based only on machine learning.
Our focus on the principles above drives accuracy in the information displayed in our solutions. But more importantly, we get confirmations of its accuracy every day in the natural course of how customers in both the public and private sectors interact with our solutions, creating a flywheel effect through which our methodology and results are constantly affirmed. Below, we’ll break down in more detail how we attribute and cluster addresses with the highest possible standard for accuracy, and how the results from those processes are confirmed to be accurate.
Building the Chainalysis blockchain knowledge graph
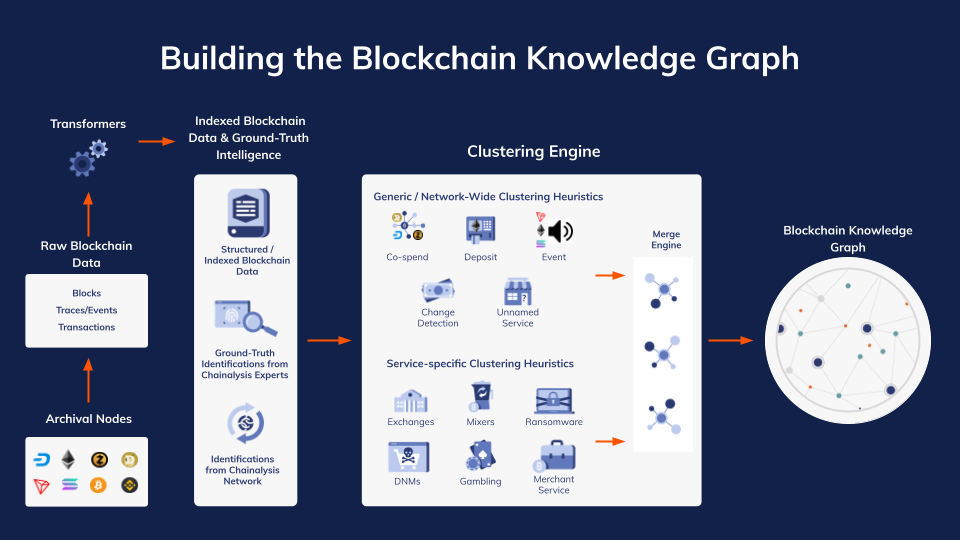
At a high level, building the Chainalysis knowledge graph consists of the two processes we discussed in the introduction.
- Ground truth address attribution
- Deterministic address clustering
We’ll break them both down below.
Ground truth address attribution
Chainalysis has a large team of blockchain intelligence and forensics experts collecting cryptocurrency addresses they can attribute to the specific real-world entities who control them.
The simplest and most common way of doing this in the case of services is by observing known transactions involving them, which allows us to identify deposit and withdrawal addresses for a given service.
We can also collect deposit addresses via open-source intelligence (OSINT), which usually means scouring online platforms (e.g. YouTube, Telegram, Reddit), clearnet and darknet web forums, and other similar platforms. Keep in mind that simply seeing the address isn’t enough — we also need to check the blockchain and confirm that someone has transacted with that address before.

Finally, Chainalysis customers also regularly share with us their own specific address attributions for inclusion in our dataset. We forward those addresses — along with our customers’ proof — to our intelligence team, which then verifies before including them as ground truth addresses and pushing them into our knowledge graph.
Deterministic address clustering
Chainalysis has clustered over a billion addresses across more than 55,000 services, wallets, and protocols. In order to do this at such scale, we build heuristics that can start with a ground truth-attributed address for a given service or wallet, then automatically identify new addresses belonging to the same service or wallet and group them all together. Those deterministic clustering heuristics are built based on the observable on-chain behavior of different types of wallets and services, and are refined through careful human review by blockchain analysis experts trained in computer science, mathematics, and cryptography.
Our deterministic clustering heuristics generally fall into one of two categories:
- Generic clustering heuristics, also known as network-wide heuristics, which can be applied to more than one service or wallet on the blockchain.
- Service-specific heuristics, which are needed when generic or network-wide clustering heuristics cannot comprehensively capture the transactional behavior of a given service. Service-specific heuristics are particularly necessary to comprehensively cluster services that intentionally obfuscate their on-chain behavior, such as mixers or darknet markets. More information on service-specific heuristics and how we develop them are available to Chainalysis customers through their account teams.
Below, we’ll take a closer look at some of our most-often used generic clustering heuristics.
Generic clustering heuristics
Generic clustering heuristics are sufficient to cluster addresses belonging to the vast majority of services and wallets on the blockchain. These heuristics include (but are not limited to) the following.
Co-spend heuristic. Co-spend identifies co-ownership of addresses by identifying Unspent Transaction Outputs (UTXOs) that are spent as inputs in the same transaction. Co-spend only applies to UTXO-based blockchains like Bitcoin. When properly implemented, these heuristics must also account for CoinJoin transactions that are specifically used in an attempt to spoil co-spend analysis.
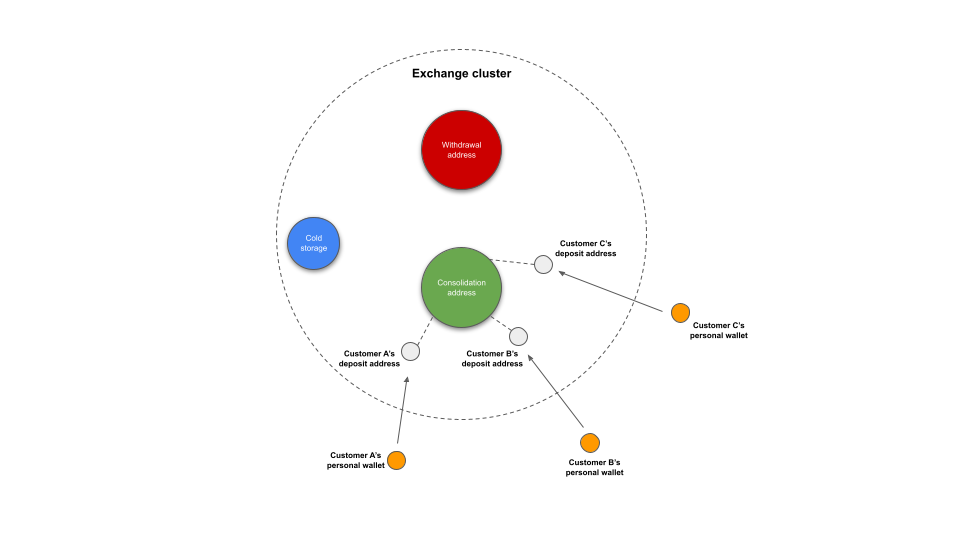
Deposit heuristic. This heuristic allows us to identify and cluster the addresses of a centralized service such as an exchange, starting from deposit addresses and following them to consolidation addresses, which are addresses used by the exchange to hold and co-mingle cryptocurrency deposited by many different users (similar to how traditional banks don’t simply hold each customer’s balance in a dedicated individual account). Deposit heuristics are primarily used to cluster addresses of services in account-based blockchains such as Ethereum.
Event-based heuristics. These heuristics cluster together addresses associated with decentralized protocols on smart contract-enabled blockchains like Ethereum by monitoring specific events carried out by the protocol’s factory contract.
Potentially unnamed service heuristics. In some cases, we identify wallets that exhibit behavior that can only be exhibited by a service, but whose real-world custodian is unknown. When that happens, we cluster the addresses together and simply label them as an unnamed service until we can identify that service based on a ground truth attribution.
How our attribution and clustering is constantly verified
While it’s not possible to audit the ownership of every address on the blockchain, in addition to the ongoing internal review and monitoring that we perform, we receive external verification of our data accuracy in two key ways. First, many of the services (e.g. exchanges) whose addresses we cluster are also Chainalysis customers who use us for transaction monitoring. As such, those customers share thousands to tens of thousands of addresses with us per day (depending on the scale of transaction activity on their platforms), allowing us to validate our clustering accuracy. As of the publish date of this blog, we have never found a discrepancy between our data and the addresses provided to us by these customers — as in, a customer has never shared an address with us via transaction monitoring that we’ve then found was incorrectly clustered with another service or wallet.
Our public sector customers are the second source of independent accuracy verification. Law enforcement agencies around the world routinely send subpoenas to cryptocurrency businesses asking for information on the owners of specific deposit addresses based on their research using Chainalysis solutions. If exchanges were responding to those subpoenas by denying ownership of the addresses in question, it would create a steady flow of inquiry from our law enforcement customers questioning the validity of our data and causing them to look for other blockchain analysis solutions.
Chainalysis has been a key solution in many law enforcement investigations that have resulted in successful convictions, as well as over $11 billion worth of asset seizures from criminals. These cases span several forms of crime, including ransomware, CSAM, stolen funds, terrorism, and scams. Documents filed by the U.S. Department of Justice also note several examples of our data’s validity, including statements from FBI agents stating that they validate Chainalysis attributions and clusters thousands of times per day, including by checking them against transactions carried out by undercover agents. In one case, agents reviewed Chainalysis data identifying 50 wallets as belonging to customers of a CSAM website on the darknet. Law enforcement was able to confirm the data was accurate in all 50 cases upon interviewing suspects and obtaining search warrants of their devices.
Our unique place in the world of cryptocurrency, serving both the public and private sectors, means that our data is tested every day in high-stakes situations, which often require collaboration among the law enforcement agencies and crypto businesses we serve. We take a comprehensive but careful and conservative approach to the attribution and clustering process, and maintain a high standard for pushing new data into our solutions.
If you’d like to learn more about Chainalysis data and how it powers our solutions, please contact us here.
End notes
[1] Note that as new transactions occur, the data inputs can change in ways that alter the information displayed in our solutions. For instance, imagine that we have a cluster for a cryptocurrency exchange that includes a consolidation wallet (meaning, an internal wallet controlled by the exchange where funds deposited by many users are held and co-mingled). If new on-chain transactions showed a new set of addresses sending funds to that consolidation wallet, we could deterministically cluster those new deposit addresses in with the exchange, and the historic transaction activity of those new addresses would now be grouped in with that of the exchange. Our solutions would therefore display previously unseen transactions for that exchange, and data points such as its lifetime value received would be different than they were previously, but only because the data inputs changed as new information came to light on-chain.
This material is for informational purposes only, and is not intended to provide legal, tax, financial, investment, regulatory or other professional advice, nor is it to be relied upon as a professional opinion. Recipients should consult their own advisors before making these types of decisions. Chainalysis does not guarantee or warrant the accuracy, completeness, timeliness, suitability or validity of the information herein. Chainalysis has no responsibility or liability for any decision made or any other acts or omissions in connection with Recipient’s use of this material.


